Prexonite Script
a .NET hosted scripting language with a focus on meta-programming and embedded DSLs
Prexonite CIL Functions
Just look at the two snippets below.
ldloc.1 ldc.i4.5 add stloc.1
Listing 1: a = a + 5 in CIL assembler
ldloci 1 ldc.int 5 add stloci 1
Listing 2: a = a + 5 in Prexonite assembler
Above you see one snippet with four CIL assembler op codes, and a second snippet that represents the exact same program, just written in Prexonite byte code assembler. The fact that the two programs look so similar is no coincidence as the Prexonite virtual machine was actually modelled after the CIL’s execution model. This exact similarity can be exploited to make Prexonite a lot faster.
A Prexonite to CIL compiler
Now before you get too excited, Prexonite Script still is what many call a “Dynamic Language” and a lot of its features are implemented in the underlying Prexonite virtual machine instead of the language compiler. Also, Prexonite byte code is not statically typed, which makes a straight translation to CIL impossible without very sophisticated data flow analysis and complete type inference. As I am not familiar with either of these topics, I decided to keep the Prexonite functions untyped.
This is where the PValue class comes into play. It encapsulates a dynamically typed piece of data and provides many methods to interact with the contained data via late binding.
In all cases, an implementation of a Prexonite function in CIL must show the exact same behaviour as the original, interpreted implementation. Functions that interact with Prexonite stack frames cannot be compiled to CIL as they are no longer executed on the virtual machine’s stack but the CLR’s instead. Therefore, CIL implementations must be able to exist alongside interpreted implementations and that as transparently as possible. Also, since the Prexonite virtual machine allows for code generation and manipulation at runtime, CIL implementations must be replaceable. This unfortunately also means that function calls inside CIL implementations cannot be statically linked as the target function might change the implementation strategy (interpreted, CIL) every moment.
How it’s done
Since the Prexonite to CIL compiler operates on Prexonite byte code, it would not make much sense to use the C# or VB CodeDOM and the corresponding compiler. Instead System.Reflection.Emit provides the necessary API. Since implementations must be replaceable, dynamic types are not an option and the so called lightweight functions are used.
The compiler is designed to operate at runtime, invoked by the running program itself. This is, because it analyses the whole application to identify functions that are not compatible with compilation to CIL. Such functions are marked with the Meta entry volatile.
The compilation process itself is actually quite straight forward. First the function is analysed in order to determine the number of temporary variables required, to build up a symbol table and to identify shared (via closures) and non-shared variables. Then the common function header is emitted including the creation of PVariable objects for shared variables and the initialisation of non-shared variables with PType.Null.
Then, the variables representing arguments are initialised with either PType.Null or the value supplied in the arguments array and finally the special variable args is set to a list of those same arguments if required by the function.
What follows is a huge loop that iterates over every instruction in the functions code and passes it into a giant switch statement, which translates every Prexonite byte code instruction into a series of CIL op codes.
Therefore, the CIL implementation of the program in Listing 2 will look like in the pseudo CIL in Listing 3.
As you can see, an untyped implementation of this simple program expands into quite some code. Notice that due to the absence of a rotation op code, the implementation requires temporary variables to insert the local stack context in the call to Addition.
ldloc var1ldc.i4.5 box int32 call IntPType PType::get_Int() newobj instance void PValue::.ctor(object, PType) stloc temp1 ldloc sctx ldloc temp1 call instance class PValue PValue::Addition(StackContext, PValue) stloc var1
Listing 3: Actual CIL implementation of the program in Listing 2
Note: I have shortened the fully qualified type names for better readability.
Is it worth the effort?
As with all optimization techniques, we must ask ourselves whether the effort for implementing it is worth the gain in performance (be it memory or speed). At this point, let me just throw the results of an amateurish micro benchmark at you.
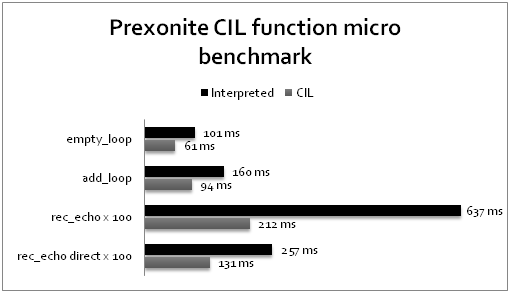
One can clearly see that CIL implementations are superior. They perform the same tasks in 60% (empty_loop) to 30% (rec_echo x 100) of the time required by the interpreted versions. Since the CIL compiler performs many of the Meta data lookups required for the creation of a stack frame at compile time, function calls to CIL implementations are much faster. Keep in mind though that only interpreted functions can take advantage of tail calls. To prevent an overflow of the managed stack, you should implement infinite recursive loops in interpreted functions.
Overall, you could say that compilation to CIL will result in a free performance improvement of over 65 percent in most cases.
function rec_echo(n) =if(n == 0)else1 + rec_echo(n-1);
function rec_echo_direct(n,r) =if(n == 0)relserec_echo(n-1,(r??0)+1);